
Storage Know-how – Info rund um unsere Storage-Systeme
Auch die beste Hochverfügbarkeit von Storagelösungen schützt nicht vor Datenverlust: Werden Daten versehentlich gelöscht, überschrieben, oder – noch schlimmer – durch Ransomware verschlüsselt hilft auch keine Redundanz. Denn dann betrifft das auch die gespiegelten Daten.
Generell werden zwei Arten von Backup unterschieden: Backup to Tape und Backup to Disk.
Backup to Tape
Traditionell werden Backups auf Magnetbänder (heute meist im LTO Format) geschrieben. Der Vorteil: Die Bänder können bei korrekten Lagerbedingungen, wie Luftfeuchtigkeit und Temperatur, bis zu 30 Jahre gelagert werden. Sie sind, wenn sicher ausgelagert, vor Veränderung geschützt, sparen Strom und sind bei großen Kapazitäten billiger als Disks.
Allerdings sind sie, wenn es darum geht, die Daten wiederherzustellen, langsam: Das Recovery dauert bei großen Datenmengen u.U. mehrere Tage. Auch die Wiederherstellung einzelner Dateien ist langwierig. Zwar gibt es mittlerweile auch LTO mit eigenem Filesystem, aber auch dann ist die Latenz sehr hoch, da das Band zur betreffenden Stelle spulen muss.
Daher wird Backup to Disk heute üblicherweise zur Langzeitarchivierung bzw. als zweite Backupstufe hinter einem aktuellen Plattenbackup verwendet.
Backup to Disk
Backupsoftware unterstützt in der Regel auch das Sichern der Dateien auf Festplatten oder SSDs, als virtuelle Tapes (was letztlich große Dateien sind, die wie Tapes verwaltet werden) oder, häufiger, als Backupdateien flexibler Größe in einem normalen Filesystem.
Backup to Disk ist durch den wahlfreien Zugriff auf die Daten wesentlich schneller, allerdings entsprechend teurer in der Anschaffung und in den Betriebskosten.
Gerade beim Backup virtueller Maschinen (VMs) kann der wahlfreie Zugriff ein wesentlicher Vorteil sein: Softwarehersteller wie Veeam unterstützen „Instant Recovery“, bei dem eine virtuelle Maschine direkt aus dem Backup gestartet wird. So sind die Daten in Minuten wieder verfügbar. Voraussetzung dafür ist die Verwendung von hochdrehenden Platten oder besser SSDs.
Vollbackup / Inkrementelles Backup
Jeden Tag ein Vollbackup zu machen ist aufwendig und erfordert viel Speicherplatz. Daher wird im Allgemeinen nur ab und zu (beispielsweise am Wochenende) ein Vollbackup gemacht. Die weiteren Backups sind dann inkrementell, d.h. nur die veränderten Daten werden gesichert. Aus dem Vollbackup und den Inkrementellen Backups kann dann der Datenstand zu einem Zeitpunkt rekonstruiert werden. Einige Softwares bieten auch die Möglichkeit, aus einem Vollbackup und den seitherigen inkrementellen Backups ein neues Vollbackup selbständig zu erstellen, so dass die Daten nicht noch einmal komplett gesichert werden müssen (Backupkonsolidierung)
Backupstrategien
Eine geeignete Backupstrategie ist wesentlich, um einerseits die benötigte Kapazität so niedrig wie möglich zu halten, andererseits aber für den Notfall auch ältere Datenstände verfügbar zu halten. Beispielsweise macht man einmal pro Woche ein Vollbackup, täglich dazu ein inkrementelles Backup. Die Vollbackups werden dann darüber hinaus ausgelagert, z.B. wöchentlich für 4 Wochen, monatlich für ein Jahr und dann jährlich. Die Lagerzeit eines Backups wird als Retention-Zeit bezeichnet.
Die Definition der Backupstrategie ist wesentlich für die Planung der Backup-Hardware, d.h. wieviel Speicherplatz auf Disk und Tape insgesamt benötigt wird.
Backup und Snapshots
Snapshots sind ein gutes Mittel, Backups zu erstellen. Für sich allein bilden sie kein echtes Backup, denn bei einem Hardwareausfall sind die ebenfalls verloren. Sie können aber als Basis für ein Backup verwendet werden, z.B. um das Backup im Hintergrund aus einem Snapshot laufen zu lassen, während weiterhin Daten verändert werden können. Aber die Snapshotdaten können auch durch asynchrone Replikation auf ein zweites repliziertes System gesichert werden. Das ZFS Filesystem unterstützt dieses Verfahren. Angewendet wird dies z.B. bei der On- & Off-Site Data Protection (OODP) der Open-E JovianDSS Software.
Backup als Schutz Ransomware
Um einen Schutz vor Ransomware zu bieten, dürfen Backups nicht in direkten Zugriff eines Filesystems sein. Ausgelagerte Bänder oder Festplatten schützen davor, aber auch Backupsysteme, die nur von der Backupsoftware selbst im Zugriff sind. Solche Lösungen bietet z.B. Veeam an mit der „Hardened Linux Immutable Repository“ Technologie, aber auch Systeme, die auf asynchroner Snapshot-Replikation beruhen und deren Volumes nur im Notfall zum externen Zugriff freigegeben werden.
Zu den EUROstor Backup Lösungen geht es hier > Backup.
Block, File und Object Storage
Block, File und Object sind Storage Formate mit denen Daten auf verschiedene Weisen gespeichert werden. Jedes hat seine Vor- und Nachteile.
Kurz zusammengefasst: Block Storage bietet einfach eine Reihe von Datenblöcken dem Client an, File Storage funktioniert über eine Ordnerhierachie (Filesystem) und Object Storage verwaltet die Daten wie in er Cloud üblich direkt mit Ihren entsprechenden Metadaten und über viele Speichersysteme hinweg.
Blockstorage
Das Block Storage basiert auf einer einfachen Methode der Datenablage. Dabei werden einzelne, physische Blöcke auf den Datendisks (HDD/SSD/NVMe) angesprochen. Jeder Block bekommt eine Art Hausnummer, Index genannt. Wird eine Datei geschrieben besteht diese Datei dann aus mehreren Blöcken und der Client „merkt“ sich den Index der Blöcke die diese Datei bilden.
Das Storage System stellt diese Blöcke einem Rechner zur Verfügung. Dieser muss die Indices selbst verwalten, entweder indem er das Volume formatiert und mit einem Filesystem seiner Wahl beschreibt, oder indem er es als Raw-Device nutzt. Die Intelligenz liegt also nicht auf dem Storage, sondern beim zugreifenden System. Ein externes Block Storage System wird also wie eine interne Festplatte behandelt. Ein RAID Verbund aus vielen Disks wird dann als eine große (virtuelle) Disk präsentiert, Block für Block.
Blockstorage wird üblicherweise direct attached oder in einer SAN (Storage Area Network) Umgebung eingesetzt. Die gängigen Protokolle beim Zugriff via Block Storage sind SAS (nur direct attached), Fibre-Channel und iSCSI (direct attached oder über einen Switch.
Dieses einfache Prinzip ermöglicht geringe Latenzen, da beim Abfragen der Daten kein bedeutender Rechenaufwand im Storage oder auf der Betriebssystemseite entsteht. Dafür steht ein Block-Volume nur einem Rechner oder Rechnercluster zur Verfügung. Bei Zugriff durch mehrere Rechner ist Filestorage vorzuziehen.
Filestorage
Das File Storage wird auch hierarchisches Storage genannt, denn im Gegensatz zum Block Storage werden nicht nur einzelne Blöcke adressiert, sondern ganze Dateien über einen Filesystem Pfad. Der Client muss den Pfad also kennen um die Datei ansteuern zu können. Mehrere Blöcke werden direkt als Datei zusammengefasst und gemeinsam mit einer begrenzten Anzahl an Metadaten auf dem Storage abgelegt. Die Ablage erfordert wegen der Filesystem-Verwaltung einen zusätzlichen Rechenaufwand im Storage selbst. Ausreichender Arbeitsspeicher ist dazu erforderlich.
File Storage ist auch bekannt als NAS (Network Attached Storage). Das Storage selbst organisiert das Filesystem, die hierarchische Struktur und die Ablage der Metadaten.
Die verbreitetsten Netzwerk Filesysteme sind CIFS (Windows) und NFS (Unix, Linux). Der wesentliche Vorteil von Filestorage besteht darin, dass mehrere Clients auf das gleiche Filesystem zugreifen können. Bei Blockstorage ist das nur über ein dediziertes Cluster Filesystem möglich.
Object Storage
Beim Object Storage liegen alle Blöcke unstrukturiert in einem großen Pool oder auch einem einzelnen Verzeichnis und werden anhand der zugehörigen Metadaten für andere Anwendungen erkennbar. Es wird nicht mehr nur ein einzelner Block oder eine einzelne Datei sondern das gesamte Objekt mit seinen Metadaten verwaltet. Diese Speicherlösung eignet sich vor allem für relativ statische Dateien, große Datenmengen (Big Data) sowie Cloud-Storage. Die gängigen Protokolle beim Zugriff via Object Storage sind REST APIs sowie SOAP (Simple Object Access Protocol) über HTTP(S).
Der Vorteil von Object Storage ist die einfache Nutzung und die nahezu unendliche Skalierbarkeit über einzelne Storage Systeme hinweg. Auch Object ist unabhängig vom Clientsystem auch hier können beliebig viele Clients gleichzeitig zugreifen.
Dadurch das nicht nur einzelne Blöcke oder Dateien betrachtet werden, sondern das gesamte Object mit all seinen Metadaten eignet sich das Object Storage nicht zwingend für Anwendungen, die geringe Latenzen erfordern, wie Datenbanken etc.
Passende Produkte von EUROstor finden Sie hier > Storage Lösungen
Ceph ist eine quelloffene Speicherlösung für Linux Systeme, die mit CephFS über ein eigenes Dateisystem verfügt. Durch Speicherung der Daten auf mehrere einzelne Systeme ist Ceph enorm flexibel und bietet hohes Scale-Out Potential.
Ceph wurde unter der Annahme entwickelt, dass alle Komponenten des Systems (Festplatten, Hosts, Netzwerke) ausfallen können, und nutzt traditionell die Replikation, um Datenbeständigkeit und Zuverlässigkeit zu gewährleisten.
Unterstützt wird Ceph beispielsweise auf CentOS, Debian, Fedora, Red Hat / RHEL, OpenSUSE und Ubuntu. Aber auch der Zugriff von Windows-Systemen aus ist möglich. Ceph findet seinen Einsatz in mittleren bis größeren Rechenzentren, ist ideal für Cloudlösungen oder auch allgemein für größere Archivlösungen.
Die Daten werden redundant auf verschiedene Datendisks, gehäuseübergreifend verteilt gespeichert und, die Ausfallsicherheit wächst mit der Anzahl unabhängiger Komponenten.
Der CRUSH-Platzierungsalgorithmus (s.u.) ermöglicht die Definition von Ausfalldomänen über Hosts, Racks, Reihen oder Rechenzentren hinweg, je nach Umfang und Anforderungen der Bereitstellung.
Der Speicher wird zusammenhängend, als ein großer Speicher, präsentiert. Dabei besteht die Möglichkeit über die verschiedensten Protokolle zuzugreifen sei es als NAS, iSCSI, über Object Protokolle oder nativ via CephFS. Die Übersetzung erfolgt durch Gateway-Daemons, die separate Knoten sein können oder als zusätzliche Prozesse auf denselben Systemen laufen.
Wichtige Komponenten eines Ceph Cluster Systems:
Monitor Nodes (MON Node)
Eine MON Node ist ein Daemon, der für die Aufrechterhaltung der Clustermitgliedschaft zuständig ist. Die MON Node schafft eine einheitliche Entscheidungsfindung für die Verteilung der Daten innerhalb des Clusters. Es benötigt wenige aber immer eine ungerade Zahl von MON-Nodes in einem System, um im Falle einer Inkonsistenz eine Quorum-Entscheidung zu treffen.
OSD Node (HDD/SSD)
Für je eine HDD oder SSD läuft ein eigener OSD Daemon, der die Speicherung der Objekte (Datenblöcke) vornimmt. Hier werden die eigentlichen Datenblöcke geschrieben und gelesen, welche zuvor über den CRUSH Algorithmus verteilt wurden.
CRUSH („Controlled Replication under Scalable Hashing“)
Das Herzstück des CEPH Konstrukts ist CRUSH, dieser Algorithmus verteilt die Datenblöcke (Objekte) anhand einer Zuordnungstabelle (CRUSH Map) pseudozufällig. Pseudozufällig deshalb, da in den zufälligen Algorithmus eingegriffen werden kann und beispielsweise eine Verteilung der Redundanz auf verschiedene Knoten, Schränke oder Brandschutzzonen vorgenommen werden kann. Sogenannte Placement Groups speichern die Objekte dann auf Wunsch räumlich redundant.
Ceph Lösungen bei EUROstor finden Sie hier.
Container:
Container sind eine Methode zur Isolierung und Bereitstellung von Anwendungen und ihren Abhängigkeiten in einer abgeschlossenen Umgebung. Jeder Container umfasst alle erforderlichen Bibliotheken, Dateien und Konfigurationen, um eine Anwendung reibungslos auszuführen. Dies führt zu einer konsistenten Umgebung, in der Anwendungen unabhängig von der zugrunde liegenden Infrastruktur ausgeführt werden können. Container sind leichtgewichtig, da sie Ressourcen effizient nutzen und schnell gestartet und gestoppt werden können.
Container-Technologien wie Docker haben die Entwicklung und Bereitstellung von Anwendungen vereinfacht, da Entwickler und Betreiber in der Lage sind, Container auf ihren lokalen Entwicklungsrechnern und in der Produktion zu verwenden. Dies ermöglicht die schnelle Entwicklung, Bereitstellung und Skalierung von Anwendungen.
Kubernetes:
Kubernetes ist ein Open-Source-Container-Orchestrierungs-System, das entwickelt wurde, um die Verwaltung und Automatisierung von Container-Anwendungen in großem Maßstab zu erleichtern. Es bietet eine leistungsstarke Plattform zur Bereitstellung, Skalierung, Aktualisierung und Verwaltung von Containern in einem Cluster von Servern. Es ermöglicht die Hochverfügbarkeit von Anwendungen, Load-Balancing, automatische Skalierung und Rollbacks bei Fehlern.
Kubernetes ist flexibel und erlaubt die Verwendung von verschiedenen Containern, einschließlich Docker, und unterstützt eine Vielzahl von Speichersystemen und Netzwerklösungen. Die Plattform bietet auch eine einfache Möglichkeit zur Verwaltung von Konfigurationen und zur Bereitstellung von Anwendungen mit minimaler Ausfallzeit.
Vorteile von Container und Kubernetes:
- Portabilität: Container sind unabhängig von der zugrunde liegenden Infrastruktur, was eine reibungslose Bereitstellung und Skalierung ermöglicht.
- Effizienz: Container sind leichtgewichtig und ressourceneffizient, was die Serverauslastung reduziert.
- Skalierbarkeit: Kubernetes ermöglicht die einfache Skalierung von Anwendungen je nach Bedarf.
- Automatisierung: Kubernetes automatisiert viele Aspekte der Anwendungsverwaltung, was Zeit und Aufwand spart.
- Hochverfügbarkeit: Kubernetes bietet Mechanismen zur Sicherstellung der Hochverfügbarkeit von Anwendungen.
Insgesamt haben Container und Kubernetes die Art und Weise, wie Unternehmen Anwendungen entwickeln und betreiben, dramatisch verändert. Sie bieten eine leistungsstarke Lösung zur Verbesserung der Effizienz, Skalierbarkeit und Zuverlässigkeit von Anwendungen in der modernen IT-Landschaft. Während die Einführung einer Container- und Kubernetes-Strategie eine Lernkurve erfordert, können die langfristigen Vorteile für Unternehmen beträchtlich sein.
Passende Produkte von EUROstor finden Sie hier > Object Storage und Cloud Storage
Beim Anschluss der RAID-Systeme an den Host-Rechner stellt sich zunächst die Frage, ob die Systeme direkt an den Rechner angeschlossen werden sollen (Direct Attached Storage, DAS) oder über ein Storage Area Network (SAN).
Letzteres ist sinnvoll, weil hier viele Systeme – Server und Storage – über Switches miteinander verbunden werden können. Ein Extremfall ist, dass nur ein Server mit vielen RAIDs verbunden wird, um viel Speicherkapazität mit entsprechender Leistung zu erhalten.
Aber auch bei Direct-Attached-Lösungen kann eine Netzwerktechnologie notwendig sein, nämlich dann, wenn Entfernungen überbrückt werden müssen, die mit SAS nicht realisierbar sind. Für Speichernetzwerke wird entweder iSCSI oder Fibre Channel verwendet. In allen Fällen, in denen kein Speichernetzwerk eingesetzt werden muss, ist SAS die kostengünstigere Alternative, da sowohl die RAID-Controller als auch die Host-Adapter in den Rechnern deutlich billiger sind.
Der Anschluss eines Speichers als NAS (Network Attached Storage) empfiehlt sich immer dann, wenn mehrere Clients gleichzeitig auf dieselben Dateisysteme zugreifen müssen. Die Verbindung ist langsamer als die oben beschriebenen blockbasierten Technologien, da sie dateibasiert ist. Ist maximale Zugriffsgeschwindigkeit gefragt, empfiehlt sich für den gemeinsamen Zugriff der Einsatz eines Cluster-Dateisystems oder entsprechender Software in Verbindung mit einer blockbasierten Speicherlösung.
| Eigenschaft | DAS | SAN | NAS |
| Bus | SAS | Fibre Channel oder Ethernet | Ethernet |
| Distanz | bis 6m | große Distanzen, abhängig vom Kabeltyp | |
| Zugriff | Block Level
(sichtbar als formattierbare Volumes)) |
File Level | |
| Anzahl Hosts | 1 oder 2 (Cluster) | viele (über Switches) | |
| Performance | fast | fast | langsamer |
| Kosten | niedrig | höher | mittel |
Passende Produkte von EUROstor finden Sie hier > RAID Systeme oder Unified Storage
Deduplikation:
Die Deduplikation, auch als „De-Duplizierung“ bezeichnet, ist eine Methode zur Entfernung redundanter Daten in einem Datensatz. Dies geschieht, indem identische Datenblöcke oder Segmente erkannt und nur einmal gespeichert werden. Der Vorteil liegt auf der Hand: Sie sparen erheblich an Speicherplatz, da nur ein einziges Exemplar der identischen Daten behalten wird. Deduplikation wird oft in Backup-Systemen, File-Servern und Storage-Systemen eingesetzt.
Kompression:
Kompression hingegen bezieht sich auf die Reduzierung der Größe von Daten, indem nicht benötigte Informationen entfernt oder durch effizientere Codierung ersetzt werden. Im Gegensatz zur Deduplikation, die auf Duplikate abzielt, zielt die Kompression darauf ab, die Daten selbst kompakter zu gestalten. Dies führt zu einer Verringerung der Speicheranforderungen und einer Beschleunigung der Datenübertragung. Kompressionstechniken werden oft in Dateikomprimierungsprogrammen, Datenbanken und beim Versenden von Dateien über das Internet verwendet.
Unterschiede und Gemeinsamkeiten:
Zielsetzung:
- Deduplikation zielt auf die Entfernung von Duplikaten innerhalb eines Datensatzes ab.
- Kompression zielt auf die Reduzierung der Gesamtgröße von Daten ab, ohne auf Duplikate beschränkt zu sein.
Effizienz:
- Deduplikation ist äußerst effizient bei Daten, die viele Duplikate enthalten, wie zum Beispiel Backup-Daten.
- Kompression ist vielseitiger und kann bei unterschiedlichen Datentypen eingesetzt werden, ist jedoch möglicherweise weniger effizient bei Daten mit vielen Duplikaten.
Anwendungsbereiche:
- Deduplikation findet häufig in Backup- und Storage-Systemen Anwendung.
- Kompression wird in einer breiteren Palette von Anwendungsfällen eingesetzt, einschließlich Dateikomprimierung und Datenübertragung.
Fazit:
Beide Technologien, Deduplikation und Kompression, haben ihren Platz in der Welt der Datenoptimierung. Die Wahl zwischen ihnen hängt von Ihren spezifischen Anforderungen und Zielen ab. Wenn Sie große Mengen an redundanten Daten haben, kann Deduplikation die beste Wahl sein, um den Speicherplatz zu maximieren. Kompression eignet sich gut, um die Gesamtgröße von Daten zu reduzieren und die Datenübertragungseffizienz zu steigern. Oftmals ist auch eine Kombination beider Techniken die optimale Lösung, um die Vorteile beider Ansätze zu nutzen und so Ihre Daten effektiv zu optimieren.
Passende Systeme von EUROstor finden Sie hier > Unified Storage
Disaster Recovery (DR):
Disaster Recovery ist ein umfassendes Konzept zur Wiederherstellung von Unternehmensdaten und -systemen nach einem schwerwiegenden Datenverlust, sei es aufgrund von Naturkatastrophen, Hardwarefehlern, menschlichem Versagen oder Cyberangriffen. Die DR-Strategie umfasst eine umfassende Planung, um sicherzustellen, dass Daten und Geschäftsprozesse schnell und zuverlässig wiederhergestellt werden können.
Die Schlüsselkomponenten der Disaster Recovery umfassen:
- Backup und Wiederherstellung: Regelmäßige Backups werden erstellt, um Daten zu sichern. Im Katastrophenfall werden diese Backups genutzt, um Daten und Systeme wiederherzustellen.
- Redundanz und Failover: Durch die Einrichtung redundanter Systeme und Failover-Mechanismen wird sichergestellt, dass Geschäftsprozesse nahtlos weiterlaufen können, selbst wenn ein System ausfällt.
- Wiederherstellungspläne: Detaillierte Pläne werden erstellt, um die Schritte zur Wiederherstellung von Daten und Systemen im Katastrophenfall festzulegen.
Offsite Data Protection (ODP):
ODP, oder Offsite Data Protection, ist ein integraler Bestandteil einer umfassenden Disaster-Recovery-Strategie. ODP bezieht sich auf die Speicherung von Daten an einem entfernten Standort, um sicherzustellen, dass Daten selbst dann verfügbar sind, wenn der primäre Standort nicht zugänglich ist. Dies kann bedeuten, dass Daten in einem externen Rechenzentrum, in der Cloud oder an einem anderen geografischen Standort gesichert werden.
Die Vorteile von ODP sind vielfältig:
- Schutz vor lokalen Katastrophen: Daten, die außerhalb des primären Standorts gespeichert sind, sind vor lokalen Katastrophen wie Bränden, Überschwemmungen und anderen Gefahren geschützt.
- Hochverfügbarkeit: ODP ermöglicht den Zugriff auf Daten von verschiedenen Standorten aus, was die Verfügbarkeit und Wiederherstellung im Katastrophenfall verbessert.
- Geografische Redundanz: Durch die Speicherung von Daten an verschiedenen Standorten wird eine geografische Redundanz erreicht, die die Datensicherheit und Verfügbarkeit weiter erhöht.
- Compliance und Regulierung: ODP kann Unternehmen dabei unterstützen, gesetzliche Anforderungen zur Datensicherung und -archivierung zu erfüllen.
Insgesamt sind Disaster Recovery und Offsite Data Protection kritische Aspekte der Unternehmenssicherheit. Sie stellen sicher, dass Unternehmensdaten geschützt und im Katastrophenfall wiederhergestellt werden können. Unternehmen, die in eine solide DR-Strategie und ODP investieren, sind besser gerüstet, um Herausforderungen und Extremsituationen zu bewältigen und die Geschäftskontinuität aufrechtzuerhalten.
Systeme mit ODP oder Disaster Recovery von EUROstor finden Sie hier > Storage Cluster
Erasure Coding:
Erasure Coding, auf Deutsch auch als „Fehlertolerante Codierung“ bekannt, ist eine fortschrittliche Technik zur Datensicherung. Hierbei werden Daten in Teilstücke (Fragments) aufgeteilt, von denen einige redundant sind und andere Informationen zur Wiederherstellung enthalten. Dies ermöglicht es, Daten wiederherzustellen, auch wenn Teile der Daten beschädigt oder verloren gehen. Erasure Coding kann Speicherplatz effizienter nutzen, da weniger Redundanz erforderlich ist, und ist somit ressourcenschonender als Replikate.
Replica (Replikation):
Die Verwendung von Replikaten ist ein traditioneller Ansatz zur Datensicherung. Hierbei werden Daten einfach kopiert, sodass mehrere identische Kopien vorhanden sind. Dies erhöht die Verfügbarkeit und die Redundanz, da Daten von mehreren Orten aus abgerufen werden können. Replikation ist eine bewährte Methode und einfach zu implementieren, aber sie verbraucht in der Regel mehr Speicherplatz als Erasure Coding.
Unterschiede und Gemeinsamkeiten:
Speichereffizienz:
- Erasure Coding ist speichereffizienter, da weniger Redundanz erforderlich ist.
- Replikate benötigen mehr Speicherplatz, da vollständige Kopien der Daten erstellt werden.
Wiederherstellbarkeit:
- Erasure Coding kann beschädigte oder verlorene Daten effizient wiederherstellen, ohne die gesamten Daten zu duplizieren.
- Bei Replikation sind die Daten bereits vorhanden, was die Wiederherstellung vereinfacht.
Verfügbarkeit:
- Durch Replikation kann die Verfügbarkeit erhöht werden, da Daten von mehreren Orten abgerufen werden können.
- Erasure Coding kann auch die Verfügbarkeit verbessern, erfordert jedoch komplexere Algorithmen.
Ressourcennutzung:
- Erasure Coding verbraucht weniger Speicherplatz, ist jedoch rechenintensiver.
- Replikate sind einfacher, erfordern jedoch mehr Speicherplatz.
Fazit:
Die Wahl zwischen Erasure Coding und Replikation hängt von den spezifischen Anforderungen und Zielen ab. Erasure Coding ist ideal für Organisationen, die effizienten Speicherplatz nutzen und gleichzeitig hohe Datenintegrität gewährleisten möchten. Replikation hingegen ist ideal, wenn hohe Verfügbarkeit und einfache Wiederherstellbarkeit priorisiert werden und zusätzlicher Speicherplatz nicht das Hauptproblem ist. Oftmals kann eine Kombination beider Methoden die beste Lösung sein, um die Vorteile von Erasure Coding und Replikation zu kombinieren und so den unterschiedlichen Anforderungen gerecht zu werden.
CEPH Systeme von EUROstor finden Sie unter > Storage auf Ceph Basis
Als Full Flash bezeichnen wir Systeme bei denen die Daten ausschließlich auf nicht flüchtigen Enterprise Chips gespeichert werden.
Umgangssprachlich sind das „Solid State Drives“ (SSDs) oder auch „Enterprise Flash Drives“ (EFDs). Enterprise Flash Drives unterscheiden sich von den gewöhnlichen Desktop SSDs durch hohe IOPS Anforderungen und umfangreichere Spezifikationen und sind daher für den kritischen Unternehmensbetrieb geeignet. Wir verwenden aller Regel nur Enterprise SSDs.
Der Vorteil gegenüber konventionellen Hard Disk Drives (HDDs) ist vor allem die Geschwindigkeit, in der Datenblöcke geschrieben oder gelesen werden können. Außerdem sind sie nicht gegen Vibrationen empfindlich.
Flash Speicher benötigt keine drehenden Zylinder, Motoren und empfindliche Lese/Schreibköpfe wie das bei den Hard Disk Drives der Fall ist.
Dadurch wird eine wesentlich schnellere Zugriffszeit auf die einzelnen Datenblöcke ermöglicht. Auch die Latenz ist durch den Wegfall physischer drehender Scheiben ein Vielfaches geringer, da nicht auch das Vorbeikommen den Blocks am Lesekopf gewartet werden muss.
Die fehlenden Vibrationen und geringerer Energieverbrauch kommt der Haltbarkeit und Temperaturentwicklung gegenüber HDDs ebenfalls entgegen. Was sich neben geringeren Stromkosten auch in den geringeren Ausfallraten gegenüber SSDs wiederspiegelt.
Statt mit SAS oder SATA werden SSDs immer häufiger mit NVMe (Nonvolatile Memory / PCIexpress – nichtflüchtiger Massenspeicher via PCIexpress) angebunden. Dies ermöglicht durch direkten Zugriff via PCIe Schnittstelle noch höheren Durchsatz bei noch geringerer Latenz.
NVMe SSDs gibt es in verschiedenen Ausführungen. Als PCIe Karten werden sie direkt in PCIe Slots gesteckt, als kleine, kompakte M.2 Modelle direkt auf die Mutterplatine (übelicherweise als Bootmedium). Für die Verwendung in hot-swap Kanistern gibt es U.2 bzw. U.3 als Standard
Der Markt bewegt sich immer weiter in die Richtung der Flash Speicher. Das Kostenverhältnis von SSDs zu HDDs mit 7200 RPM lag pro TB 2013 bei ca. 37:1 . 2021 sind es 4,2:1. Aktuellen Schätzungen zu Folge, werden Flash Speicher die HDDs bis 2026 beim Preis per TB eingeholt haben und darüber hinaus wohl sogar billiger sein als HDDs. Schon heute spielen daher 15K rpm Drives keine Rolle mehr und auch 10K verschwindet mehr und mehr vom Markt.
Full-Flash Systeme von EUROstor finden Sie hier > Full-Flash
Als hochverfügbar (HA, „high availability“) werden Systeme bezeichnet die eine Verfügbarkeit von 99%+ aufweisen. Für einen dauerhaften Betrieb der Infrastruktur ist dieses Konzept daher unerlässlich.
Hochverfügbarkeit kann lokal sein, über Brandschutzzonen hinweg oder sogar georedundant.
Ein System das beispielsweise in einem einzelnen Raum eine Hochverfügbarkeit aufweist ist nicht verfügbar, wenn dieser Raum als Ganzes nicht mehr erreichbar ist. Es ist also wichtig zu wissen, welche Art der Hochverfügbarkeit für die eigene Infrastruktur Sinn macht und notwendig ist.
Hochverfügbarkeit definiert sich durch zwei oder mehrere (unabhängige) Systeme die aktiv auf die Infrastruktur zugreifen können, sodass bei Ausfall eines der Systeme das andere automatisch die Dienste übernehmen kann. Einzelne Hardware-Komponenten können daher ausfallen ohne den Betrieb zu beeinträchtigen. Hier wird auch oft von „No Single Point of Failure“ NOSPF gesprochen.
Ein Standby System welches erst in die aktive Infrastruktur eingebunden werden muss kann allenfalls als Desaster Recovery Lösung bezeichnet werden. Auch das klassische RAID bietet eine Hochverfügbarkeit nur innerhalb des eigenen Verbundes (lokal, auf die Disks/SSDs bezogen).
Zwei Rechner oder Storage Systeme, die gemeinsam ein hochverfügbares System bilden, werden als HA-Cluster bezeichnet. Ist eines der Systeme im Standby Modus und übernimmt nur im Fehlerfall, spricht man von einem active/passive Cluster. Sind beide aktiv und übernehmen im Fehlerfall die Aufgaben des anderen Systems zusätzlich, handelt es sich um einen active/active Cluster. Wichtig ist, dass die Übernahme im Fehlerfall automatisch, ohne manuelles Eingreifen, geschieht.
Das Maximum an Sicherheit und Verfügbarkeit wird durch Kombination von Cluster Systemen in Verbindung einer Replikation auf ein Desaster Recovery System erreicht. Das ZFS Dateisystem bietet hierfür praktische Funktionen.
Hochverfügbare Cluster Systeme finden Sie hier > Storage Cluster
Was ist Hyperconverged?
Hyperconverged ist eine IT-Infrastrukturstrategie, die darauf abzielt, die Effizienz und Agilität von Rechenzentren zu erhöhen. Sie erreicht dies, indem sie Rechenleistung, Speicher und Netzwerkressourcen in einem einzigen integrierten System zusammenführt. Diese Ressourcen werden in der Regel über eine einzige Management-Schnittstelle verwaltet, was die Verwaltung und Skalierung erheblich vereinfacht.
Vorteile der Hyperconverged:
- Einfache Verwaltung: Durch die Integration von Rechenleistung, Speicher und Netzwerkfunktionen in einer einzigen Plattform wird die Verwaltung der IT-Infrastruktur erheblich vereinfacht. Dies führt zu Zeit- und Kosteneinsparungen.
- Skalierbarkeit: Hyperconverged erlaubt es Unternehmen, ihre Infrastruktur bei Bedarf zu erweitern, indem sie einfach weitere Module hinzufügen. Dies ermöglicht eine nahtlose Anpassung an wachsende Anforderungen.
- Effizienz: Durch die Konsolidierung von Ressourcen auf einer Plattform kann die Ressourcenauslastung optimiert und der Hardwarebedarf reduziert werden. Dies führt zu geringerem Platzbedarf und niedrigeren Energiekosten.
- Hohe Verfügbarkeit: Hyperconverged Systeme bieten in der Regel integrierte Mechanismen zur Gewährleistung der Hochverfügbarkeit, um Ausfallzeiten zu minimieren.
- Flexibilität: Die meisten Hyperconverged -Lösungen sind hardwareunabhängig und bieten die Freiheit, die Hardwarekomponenten auszuwählen, die den eigenen Anforderungen am besten entsprechen.
Anwendungsbereiche von Hyperconverged:
Hyperconverged findet in einer Vielzahl von Anwendungsbereichen Anklang, darunter:
- Virtualisierung: Hyperconverged Infrastrukturen sind ideal für die Bereitstellung von Virtualisierungsplattformen, da sie die Verwaltung von virtuellen Maschinen vereinfachen.
- Private Clouds: Unternehmen nutzen Hyperconverged, um kosteneffiziente und skalierbare private Cloud-Infrastrukturen zu erstellen.
- Remote und Zweigstellen (ROBO): Hyperconverged ermöglicht es, die IT-Infrastruktur in remote und Zweigstellen zu konsolidieren und zu vereinfachen.
- Backup und Wiederherstellung: Hyperconverged bietet eine effiziente Lösung für Backup und Wiederherstellung von Daten.
Insgesamt hat Hyperconverged die Art und Weise, wie Unternehmen ihre IT-Infrastruktur gestalten und betreiben, revolutioniert. Mit seinen Vorteilen in Bezug auf einfache Verwaltung, Skalierbarkeit und Effizienz ist Hyperconverged zu einer attraktiven Option für Organisationen geworden, die ihre IT-Infrastruktur modernisieren und optimieren möchten.
Passende HyperConverged Systeme von EUROstor finden Sie unter > Hyperconverged Storage
Der Proxmox Backup Server (PBS) ist eine leistungsstarke Lösung für die zuverlässige Sicherung und Wiederherstellung von Daten in virtualisierten Umgebungen. Entwickelt von den Machern von Proxmox Virtual Environment (VE), integriert der PBS nahtlos in bestehende Proxmox VE-Infrastrukturen und bietet eine benutzerfreundliche Plattform für effizientes Datenmanagement.
Wichtige Funktionen des Proxmox Backup Servers:
- Komplette Virtualisierungssicherung:
Der PBS ermöglicht die Sicherung von gesamten virtuellen Maschinen, einschließlich der Konfigurationen, Snapshots und Festplatteninhalte. Dadurch ist eine umfassende und wiederherstellbare Datensicherung gewährleistet.
- Inkrementelle Datensicherung:
Mit der Unterstützung inkrementeller Backups werden nur die Änderungen seit dem letzten Backup gesichert. Dies spart Speicherplatz und beschleunigt den Sicherungsprozess erheblich.
- Flexible Speichermanagementoptionen:
Der PBS ermöglicht die Integration verschiedener Speicherziele, einschließlich lokaler Server, Netzwerkfreigaben und Cloud-Dienste. Diese Flexibilität erleichtert die Anpassung an die individuellen Bedürfnisse jeder IT-Infrastruktur.
Datenverschlüsselung und Sicherheit:
- Mit der integrierten Verschlüsselung von Datenübertragungen und Speichermedien gewährleistet der PBS höchste Sicherheitsstandards für sensible Unternehmensdaten.
- Benutzerfreundliches Webinterface:
Das intuitiv gestaltete Webinterface ermöglicht eine einfache Konfiguration, Überwachung und Verwaltung von Backup-Jobs. Dies vereinfacht den gesamten Sicherungsprozess für Administratoren.
- Proxmox VE-Integration:
Als integraler Bestandteil der Proxmox-Familie ermöglicht der PBS eine nahtlose Integration mit Proxmox VE. Dies erleichtert die Einrichtung, Verwaltung und Nutzung der Backup-Infrastruktur innerhalb der Proxmox-Umgebung.
Passende Systeme von EUROstor finden Sie hier > Proxmox Backup Server
Proxmox Virtual Environment (Proxmox VE) ist eine umfassende Open-Source-Plattform, die Virtualisierung und Storage-Management in einer benutzerfreundlichen Umgebung integriert. Mit Proxmox VE haben Sie die Möglichkeit, virtuelle Maschinen und Container zu erstellen, zu verwalten und zu überwachen, sowie eine leistungsstarke Integration von Ceph Storage und ZFS, um Ihre Daten effizient zu speichern und zu sichern.
Virtualisierung mit Proxmox VE:
Proxmox VE bietet eine flexible Virtualisierungslösung, die sowohl für Unternehmen als auch für Privatanwender geeignet ist. Durch die Integration von KVM (Kernel-based Virtual Machine) als Hypervisor und dem leistungsstarken OpenVZ für Container-Virtualisierung ermöglicht Proxmox VE die einfache Bereitstellung und Verwaltung von virtuellen Maschinen und Containern auf einer einzigen Plattform.
Die Hauptmerkmale der Virtualisierungsfunktionen von Proxmox VE sind:
- Benutzerfreundliches Webinterface: Das intuitive Webinterface ermöglicht eine einfache Konfiguration, Überwachung und Verwaltung Ihrer virtuellen Umgebung.
- Live-Migration: Nahtlose Migration von virtuellen Maschinen zwischen physischen Hosts ohne Ausfallzeiten für erhöhte Flexibilität.
- Backup und Wiederherstellung: Mühelose Sicherung und Wiederherstellung Ihrer virtuellen Umgebung zur Gewährleistung von Datenintegrität und Ausfallsicherheit. Proxmox bietet hierfür eine eigens entwickelt Plattform an, Proxmox Backup Server.
- Unterstützung für Linux- und Windows-Gastsysteme: Vielfältige Unterstützung für verschiedene Betriebssysteme zur Erfüllung unterschiedlicher Anforderungen.
CEPH Integration:
Die Integration von Ceph, einem leistungsstarken verteilten Speichersystem, macht Proxmox VE zu einer umfassenden Lösung für Ihre Speicheranforderungen. Ceph bietet skalierbaren, hochverfügbaren und fehlertoleranten Speicher, der sich nahtlos in Proxmox VE integrieren lässt. Hier sind einige Schlüsselfunktionen der Ceph-Integration:
- Objekt-, Block- und Dateispeicher: Ceph unterstützt verschiedene Speichermodelle, was die Anpassung an unterschiedliche Workloads ermöglicht.
- Erweiterte Skalierbarkeit: Ceph kann horizontal skaliert werden, um mit dem Wachstum Ihrer Datenanforderungen Schritt zu halten.
- Automatische Replikation: Daten werden automatisch auf verschiedene Knoten repliziert, um Datenintegrität und Verfügbarkeit sicherzustellen.
- Selbstheilungsfunktionen: Ceph erkennt und behebt automatisch Fehler, um kontinuierliche Datenverfügbarkeit zu gewährleisten.
ZFS Integration:
Als Alternative zur Ceph-Integration bietet Proxmox VE die Möglichkeit, das fortschrittliche Dateisystem ZFS zu verwenden. ZFS (Zettabyte File System) bietet erweiterte Funktionen wie:
- Datenintegrität und Fehlererkennung: ZFS verwendet Prüfsummen, um Datenintegrität sicherzustellen und Fehler automatisch zu erkennen und zu korrigieren.
- Snapshots und Clones: ZFS ermöglicht das einfache Erstellen von Snapshots für die Momentaufnahme von Dateisystemen sowie das Erstellen von Clones für effizientes Klonen von Daten.
- Effiziente Speichernutzung: Durch die Kombination von Speicherressourcen und eine intelligente Komprimierung bietet ZFS eine effiziente Speichernutzung.
Zusammengefasst CEPH vs ZFS:
Speicherarchitektur:
- Ceph: Verteiltes Speichersystem für skalierbare und verteilte Architekturen.
- ZFS: Fortschrittliches Dateisystem für effiziente Speichernutzung und Datenintegrität.
Skalierbarkeit:
- Ceph: Skaliert horizontal, ideal für große Datenmengen und verteilte Umgebungen.
- ZFS: Skalierung auf einzelnen Servern, optimal für umfangreiche Datensicherung und -integrität.
Datenverteilung:
- Ceph: Automatische Verteilung von Daten über mehrere Knoten für hohe Verfügbarkeit und Fehlerbehebung.
- ZFS: Interne Verteilung und Spiegelung für Datenintegrität.
Anwendungsbereiche:
- Ceph: Optimal für verteilte Cloud-Speicherumgebungen.
- ZFS: Geeignet für lokale Datensicherung, virtuelle Maschinen und hohe Datensicherheit.
Proxmox VE bietet Unternehmen mit der Integration von Ceph und ZFS eine umfassende Lösung für Virtualisierung und Storage-Management. Die Auswahl zwischen Ceph und ZFS hängt von den spezifischen Anforderungen und Architekturpräferenzen ab, wodurch Proxmox VE eine flexible und leistungsstarke Plattform für unterschiedlichste IT-Szenarien wird. Entdecken Sie die Vorteile von Proxmox VE und gestalten Sie Ihre Virtualisierungs- und Speicherumgebung nach Ihren individuellen Bedürfnissen hier > Proxmox Cluster
Open-e JovianDSS ist ein ZFS-basiertes Speichersystem, das speziell für Unternehmensanwendungen entwickelt wurde. Es nutzt die Vorteile des ZFS-Dateisystems, um eine hohe Datenintegrität, Skalierbarkeit und Leistung zu gewährleisten. Es verwendet fortschrittliche Technologien wie Tiering, Deduplizierung und Komprimierung, um die Speichernutzung zu optimieren und die Leistung zu verbessern. Darüber hinaus bietet es Funktionen wie automatisches Failover und Disaster Recovery, um die Datenverfügbarkeit zu gewährleisten.
Vorteile:
- Hohe Datenintegrität: Durch die Verwendung von ZFS kann Open-e JovianDSS Datenkorruption verhindern und sicherstellen, dass die Daten unverändert bleiben.
- Skalierbarkeit: Es kann problemlos skaliert werden, um den wachsenden Speicheranforderungen von Unternehmen gerecht zu werden.
- Leistung: Durch die Verwendung von Technologien wie Tiering und Caching kann es eine hohe Leistung bieten.
- Datenverfügbarkeit: Mit Funktionen wie automatischem Failover und Disaster Recovery kann es eine hohe Datenverfügbarkeit gewährleisten.
Vorteil gegenüber herkömmlichen RAID-Systemen: Im Vergleich zu herkömmlichen RAID-Systemen bietet Open-e JovianDSS eine Reihe von Vorteilen. Erstens bietet es eine höhere Datenintegrität durch die Verwendung von ZFS, das Datenkorruption verhindern kann. Zweitens bietet es eine bessere Skalierbarkeit und kann problemlos erweitert werden, um den wachsenden Speicheranforderungen von Unternehmen gerecht zu werden. Drittens bietet es durch die Verwendung von Technologien wie Tiering und Caching eine höhere Leistung. Schließlich bietet es durch Funktionen wie automatisches Failover und Disaster Recovery eine höhere Datenverfügbarkeit.
Einsatzszenarien: Open-e JovianDSS kann in einer Vielzahl von Szenarien eingesetzt werden, darunter:
- Datenintensive Anwendungen: Aufgrund seiner hohen Leistung und Skalierbarkeit ist es ideal für datenintensive Anwendungen wie Big Data und Analytics.
- Virtualisierung: Es bietet robuste Funktionen für die Speicherung von virtuellen Maschinen und kann in Umgebungen mit hoher Dichte eingesetzt werden.
- Backup und Disaster Recovery: Mit seinen robusten Disaster Recovery-Funktionen kann es als primäres oder sekundäres Backup-System für kritische Daten eingesetzt werden.
Details des Systems können je nach Ihrer spezifischen Konfiguration und Nutzung variieren. Kontaktieren Sie uns für eine individuelle Beratung. > Jovian DSS Metro Cluster
Vor 1987 wurden Daten für Unternehmen und Großrechner meist auf einzelne große und sehr teure Speicherblöcke gesichert. Kleinere und günstigere Festplatten waren überwiegend für die Personal Computer vorgesehen.
Mit zunehmender Wichtigkeit und Menge der Daten konnten sich Unternehmen einen Verlust dieser einzelnen großen Disk nicht mehr leisten. Alle Daten waren bei Ausfall der Disk verloren.
Daraus entstand der Gedanke mehrere kleine Festplatten zu einem größeren logischen Verbund zusammen zu schalten, um zum einen die Kosten auf viele kleine Disks zu verteilen und zum anderen zu gewährleisten das eine einzelne kleine Disk ausfallen darf ohne den logischen Verbund und die Daten darauf zu verlieren.
Der Begriff RAID – Redundant Array for Inexpensive Disks war geboren. Die Daten wurden verteilt auf mehrere Festplatten geschrieben und erhielten Zusatzinformationen an den jeweiligen Blöcken. Sogennante Redundanz-Informationen oder auch Parity-Data genannt. Aus diesen Paritätsdaten konnte die CPU ausgefallene Datenblöcke wieder auf neue Festplatten rekonstruieren.
Somit konnte ein Teil des Verbundes ausfallen, welcher durch die Redundanz-Blöcke wieder auf neue unbeschriebenen Festplatten wiederhergestellt werden konnte.
Da große einzelne Disks der Vergangenheit angehören und für Unternehmen Ausfallsicherheit und Performance eine größere Rolle spielen als der Preis spricht man bei RAID mittlerweile lieber von „Redundant Array of *Independent* Disks.
Darüber hinaus hatte es einen Geschwindigkeitsvorteil, wenn eine Datei verteilt auf mehrere Festplatten geschrieben oder gelesen werden konnte, da hier der Zugriff auf die einzelnen Blöcke parallel erfolgt.
Die RAID Level
Die verschiedenen RAID Level unterscheiden die Art des Verbundes der einzelnen Festplatten. Redundanz, Geschwindigkeit und Kapazität sind dabei die entscheidenden Faktoren.
Die gängigsten RAID Level sind RAID 0, RAID 1, RAID 10, RAID 5 (50) und RAID 6 (60).
Bei RAID 0 werden die Daten gleichmäßig auf alle Platten verteilt geschrieben (striping), was zwar die Performance erhöht und eine große virtuelle Platte erstellt, aber es gibt keine Redundanz, d.h. der Ausfall einer Platte führt zum Ausfall des ganzen RAIDs. RAID 0 wird daher nur verwendet wenn schneller Zugriff erforderlich ist, aber die Daten bei einem Fehler jederzeit wiederhergestellt werden können.
Bei einem RAID 1 werden zwei Festplatten miteinander gespiegelt, daher redet man auch von einem “Mirror”. Der RAID Controller muss keinerlei Paritätsdaten berechnen, da einfach jeder geschriebene Block auf beide Disks geschrieben wird. Fällt eine der Festplatten aus hat die andere Festplatte exakt denselben Datenbestand vorgehalten und kann diesen bei Austausch gegen eine neue Festplatte wieder spiegeln. Die Kapazität ist durch die Spiegelung jedes Datenblocks die einer der Festplatten im Spiegel, also 50% der Gesamtkapazität des Verbundes.
Die Schreibleistung entspricht ebenfalls der einer Festplatte, beim Lesen wiederum kann von beiden Festplatten je ein Teil der angeforderten Daten parallel gelesen werden was die Leseleistung bei RAID1 steigert.
Ein RAID 10 ist ein Verbund mehrerer RAID 1 Spiegel, die Daten werden über alle Spiegel verteilt (striping), somit lassen sich eine Vielzahl an Festplattenspiegel in einem logischen Verbund realisieren. Die Performance erhöht sich entsprechend wie bei RAID 0, allerdings liegt der Verschnitt bei 50%.
Bei RAID 5 werden die Daten wie bei RAID 0 gestriped, auf eine der Platten wird aber die Parity über die anderen Platten geschrieben. So können bei Ausfall einer Platte aus allen anderen Platten plus der Parity Information die fehlenden Daten rekonstruiert werden. Um eine gleichmäßige Belastung der Platten Zugriff zu gewährleisten, wird die Parityinformationen pro Datensatz auf wechselnde Platten verteilt. Andernfalls müsste bei jedem Schreibzugriff auch die Parity Platte beschrieben werden, das die Performance deutlich reduzieren würde. Der Verschnitt liegt hier bei n-1 (bei beispielsweise 12 Disks steht die Kapazität von 11 zur Verfügung.)
RAID 6 nutzt ein komplexes mathematisches Verfahren, die eine doppelte Parity zu berechnen. Hier können zwei Platten ohne Datenverlust ausfallen. Der Aufwand führt zu einer etwas geringeren Performance, rechtfertigt sich aber: Da ein Rebuild einer Platte u.U. viele Stunden dauert, wäre bei RAID 5 in dieser Zeit auch ein einzelner Lesefehler auf einer anderen Disk schon nicht mehr behebbar. Der Verschnitt liegt hier bei n-2, da die Kapazität zweier Platten für die doppelte Parität genutzt wird.
Bei RAID 50 bzw. 60 werden mehrere RAID 5/6 Sets zu einem Stripeset zusammengefasst. Hier können also pro Set eine bzw. zwei Festplatten ohne Datenverlust ausfallen.
Welches RAID Level ist optimal?
Das hängt natürlich von der Anwendung ab. RAID 10 ist sehr sicher und vor allem schnell, kostet aber den Einsatz von doppelt so vielen Festplatten. Bei großen, drehenden Platten ist normalerweise RAID 6 dringend empfohlen. Bei SSDs verwendet man je nach Performanceanspruch RAID 10 (teurer) oder RAID 5 (deutlich performanter als RAID 6, aber der Rebuild dauert nicht so lange, daher ist das Risiko geringer)
Hardware RAID – Software RAID
Ein RAID Set wird entweder durch einen dedizierten Controller mit eigenem Prozessor (Hardware RAID) realisiert, kann aber auch vom Betriebssystem eines Rechners selbst erstellt werden (Software RAID). Letzteres ist zum Beispiel der Fall, wenn zwei Bootplatten als RAID 1 gespiegelt werden. In den meisten anderen Fällen und natürlich bei externem Speicher ist ein RAID Controller in der Regel performanter und einfacher zu managen.
Zu den EUROstor RAID Systemen geht es hier > Raid Systeme.
Remote Direct Memory Access (RDMA)
RDMA ermöglicht, wie der Name schon sagt, den direkten Austausch von Daten im Arbeitsspeicher zwischen zwei oder mehreren Servern. Der Austausch der Daten erfolgt unabhängig von CPU, Cache oder Betriebssystem. Durch ein direkt in der Netzwerkkarte implementiertes Transportprotokoll (RoCE/IWARP/InfiniBand) können Daten zwischen zwei RDMA fähigen Servern mit viel höheren Durchsätzen und einer wesentlich geringeren Latenz durchgereicht werden.
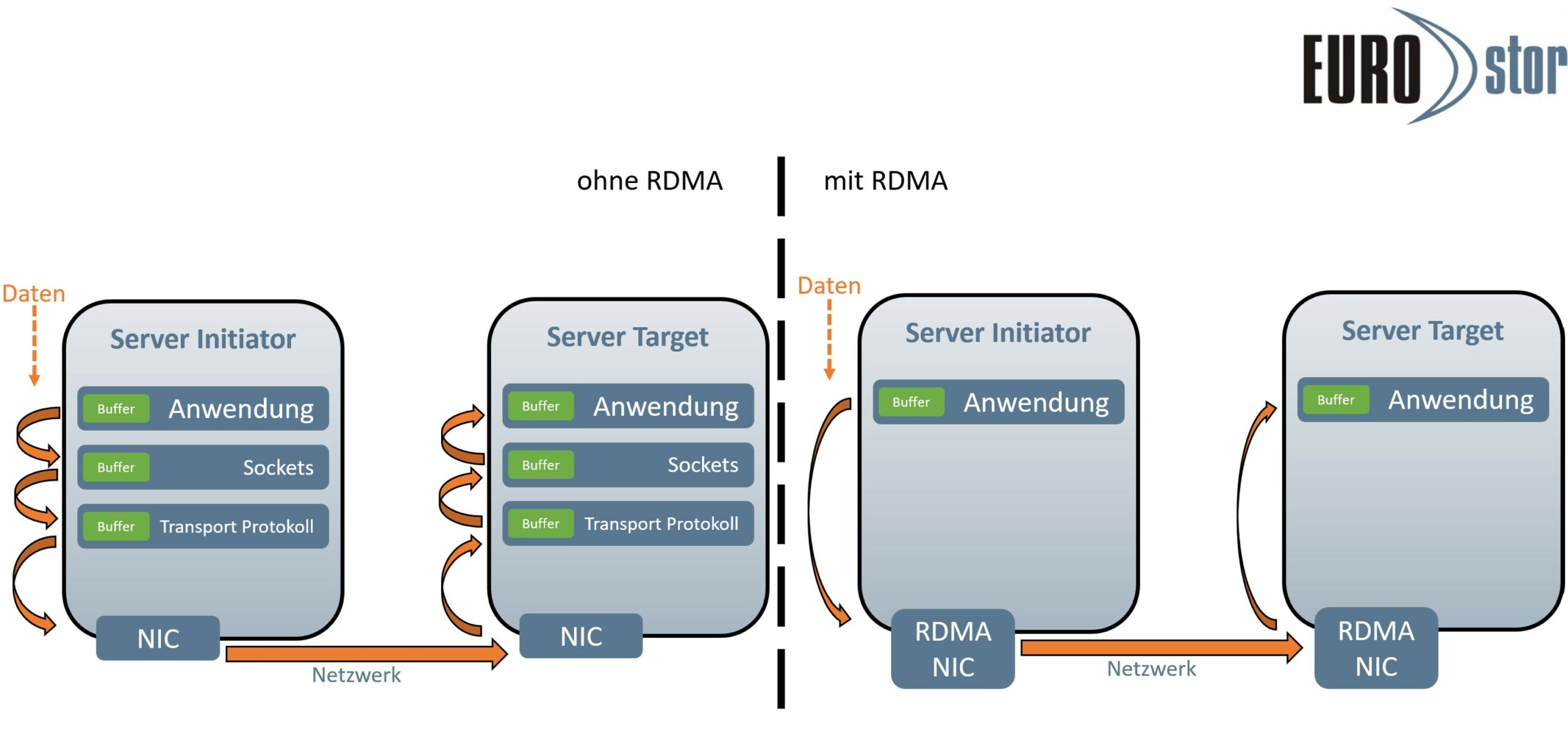
Die Anwendungsdaten im Arbeitsspeicher können direkt an die RDMA Netzwerkkarte gesendet werden, welche dann eines der RDMA Protokolle nutzt um diese über das Netzwerk an den anderen RDMA fähigen Server zu senden. Der RDMA NIC am Target gibt die Daten dann direkt an den Arbeitsspeicher weiter ohne auf CPU, Treiber oder weitere Netzwerkprotokolle angewiesen zu sein.
RDMA kann auch über bestehende Ethernet Infrastrukturen eingerichtet werden, es ist nicht notwendig, die komplette Netzwerkstruktur an RDMA anzupassen.
- RDMA over Converged Ethernet (RoCE) ermöglicht RDMA in bestehenden Ethernet Netzwerken.
- Internet Wide Area RDMA-Protokoll (IWARP) nutzt das TCP oder SCTP Protokoll
- Für InfiniBand ist RDMA das Standardprotokoll und wird häufig in HPC Umgebungen genutzt.
HPC, BigData oder Supercomputing sind die Bereiche in denen RDMA häufig Einsatz findet. Aber auch die Reduktion der Workloads für Datenbanken bietet sich an.
Gerade bei Full- Flash Systemen mit SSDs oder NVMe‘s bietet sich RDMA an. Die geringe Antwortzeit des Flashspeichers wurde in der Vergangenheit durch Netzwerkprotokolle, Controller etc. zunichte gemacht. Der Flaschenhals war dann nicht mehr, wie bei HDDs, das Speichermedium selbst.
NVDIMMs (Non-volatile Dual In-Line Memory Module), sind Arbeitsspeichermodule mit der Fähigkeit Daten dauerhaft zu speichern. NVDIMMs bieten sich daher hervorragend für SAN Systeme in Rechenzentren an. In Verbindung mit RDMA eine einfach zu implementierende und performante Lösung für gehäuseübergreifende und hochverfügbare Clustersysteme.
Passende Produkte von EUROstor finden Sie hier > ZFS Metro Cluster
Was ist Scale-Out?
Scale-Out, auch als horizontaler Skalierung bezeichnet, ist eine Methode zur Erweiterung der Serverinfrastruktur, indem neue Server hinzugefügt werden, um die Last auf das Netzwerk zu verteilen und die Gesamtleistung zu steigern. Anstatt nur einen einzelnen, leistungsstarken Server zu verwenden, werden mehrere Server mit ähnlichen Spezifikationen in einem Cluster kombiniert. Dies ermöglicht es Unternehmen, die benötigte Rechenleistung und Speicherkapazität flexibel anzupassen.
Vorteile von Scale-Out:
- Skalierbarkeit: Scale-Out bietet die Möglichkeit, die Serverinfrastruktur nach Bedarf zu erweitern, was eine einfache Anpassung an wachsende Anforderungen ermöglicht.
- Hochverfügbarkeit: Durch die Verteilung von Workloads auf mehrere Server wird die Ausfallsicherheit erhöht, da ein Serverausfall nicht zwangsläufig zu einem Ausfall der gesamten Infrastruktur führt.
- Lastverteilung: Scale-Out ermöglicht eine gleichmäßige Verteilung der Arbeitslast auf mehrere Server, was die Leistung insgesamt steigert und Engpässe verhindert.
- Kosteneffizienz: Anstatt in teure Einzelserver zu investieren, können Unternehmen kostengünstigere Standardserver verwenden, was die Gesamtkosten reduziert.
- Flexibilität: Unternehmen haben die Flexibilität, die Serverinfrastruktur je nach Bedarf anzupassen und die Ressourcen dynamisch zuzuweisen.
Anwendungsbereiche von Scale-Out:
Scale-Out findet in einer Vielzahl von Anwendungsbereichen Anwendung, darunter:
- Webdienste: Unternehmen, die webbasierte Dienste anbieten, können Server ScaleOut verwenden, um den Datenverkehr zu bewältigen und die Leistung ihrer Dienste zu optimieren.
- Datenbanken: Die Skalierung von Datenbankservern ist ein gängiger Anwendungsfall für Server ScaleOut, um die Leistung bei großen Datenmengen zu gewährleisten.
- Virtualisierung: Server ScaleOut kann in virtualisierten Umgebungen eingesetzt werden, um die Ressourcen für virtuelle Maschinen effizient zu verwalten.
- Big Data-Analyse: Unternehmen, die große Datenmengen analysieren, nutzen Server ScaleOut, um die Verarbeitungsgeschwindigkeit zu steigern und Echtzeit-Analysen zu ermöglichen.
Systeme mit Scale-Out von EUROstor finden Sie hier > Scale-Out Storage Cluster
Snapshots sind eine wichtige Funktion in der Informationstechnologie, insbesondere im Bereich der Datenverwaltung und Virtualisierung. Ein Snapshot, zu Deutsch „Momentaufnahme“ oder „Schnappschuss“, bezieht sich auf einen Zustand, der zu einem bestimmten Zeitpunkt in der IT-Umgebung festgehalten wird. Dieser Zustand kann verschiedene Arten von Daten oder Systemen betreffen, einschließlich Dateien, virtuelle Maschinen, Datenbanken und vieles mehr. Snapshots dienen dazu, den aktuellen Zustand zu archivieren, um ihn später für verschiedene Zwecke zu nutzen.
Verwendungszwecke von Snapshots
– Datensicherung und Wiederherstellung Snapshots ermöglichen es, Daten in einem stabilen Zustand zu speichern. Dies ist besonders wichtig, um im Falle eines Datenverlusts oder Fehlfunktionen eine schnelle Wiederherstellung zu ermöglichen.
– Fehlerbehebung und Testing IT-Profis verwenden Snapshots oft, um vor Änderungen oder Updates einen Sicherheitsnetz-Zustand zu erstellen. Falls Probleme auftreten, können sie leicht zu diesem Zustand zurückkehren, um Fehler zu beheben und Tests durchzuführen.
– Effiziente Ressourcennutzung In virtuellen Umgebungen wie Servervirtualisierung ermöglichen Snapshots die Erstellung von Klonen von virtuellen Maschinen ohne die Notwendigkeit einer vollständigen Kopie. Dadurch werden Ressourcen effizienter genutzt.
– Versionskontrolle Snapshots sind nützlich, um verschiedene Versionen von Daten oder Systemen zu verwalten. Dies ist in der Softwareentwicklung und im Datenbankmanagement von großer Bedeutung.
Funktionsweise von Snapshots
Die Funktionsweise von Snapshots kann je nach der Art der IT-Umgebung variieren. In der Regel wird jedoch ein Snapshot erstellt, indem ein Bild des aktuellen Zustands einer Ressource gemacht wird. Dieses Bild enthält alle relevanten Daten und Metadaten, um den Zustand vollständig zu rekonstruieren. Der Snapshot wird separat gespeichert, unabhängig von der ursprünglichen Ressource.
Es ist wichtig zu beachten, dass Snapshots in der Regel schreibgeschützt sind, um den Zustand zu bewahren und unbeabsichtigte Änderungen zu verhindern. Falls erforderlich, können Benutzer den Snapshot in der Regel jedoch in eine aktive Ressource umwandeln, um Änderungen vorzunehmen.
Vor- und Nachteile von Snapshots
Vorteile von Snapshots sind die Fähigkeit zur schnellen Wiederherstellung von Daten, die Unterstützung für effiziente Ressourcennutzung und die einfache Verwaltung von Versionen. Sie sind jedoch nicht für alle Szenarien geeignet. Snapshots erfordern zusätzlichen Speicherplatz und können die Leistung beeinträchtigen, wenn sie missbräuchlich verwendet werden.
Insgesamt sind Snapshots ein wertvolles Werkzeug in der IT, das dazu beiträgt, Daten und Systeme zu schützen, Fehler zu beheben und die Effizienz zu steigern. Die Verwendung von Snapshots erfordert jedoch eine sorgfältige Planung und Überwachung, um ihre Vorteile optimal auszuschöpfen und mögliche Nachteile zu minimieren.
Snapshots sind eine wichtige Funktion in der Informationstechnologie, insbesondere im Bereich der Datenverwaltung und Virtualisierung. Ein Snapshot, zu Deutsch „Momentaufnahme“ oder „Schnappschuss“, bezieht sich auf einen Zustand, der zu einem bestimmten Zeitpunkt in der IT-Umgebung festgehalten wird. Dieser Zustand kann verschiedene Arten von Daten oder Systemen betreffen, einschließlich Dateien, virtuelle Maschinen, Datenbanken und vieles mehr. Snapshots dienen dazu, den aktuellen Zustand zu archivieren, um ihn später für verschiedene Zwecke zu nutzen.
Verwendungszwecke von Snapshots
– Datensicherung und Wiederherstellung: Snapshots ermöglichen es, Daten in einem stabilen Zustand zu speichern. Dies ist besonders wichtig, um im Falle eines Datenverlusts oder Fehlfunktionen eine schnelle Wiederherstellung zu ermöglichen.
– Fehlerbehebung und Testing: IT-Profis verwenden Snapshots oft, um vor Änderungen oder Updates einen Sicherheitsnetz-Zustand zu erstellen. Falls Probleme auftreten, können sie leicht zu diesem Zustand zurückkehren, um Fehler zu beheben und Tests durchzuführen.
– Effiziente Ressourcennutzung: In virtuellen Umgebungen wie Servervirtualisierung ermöglichen Snapshots die Erstellung von Klonen von virtuellen Maschinen ohne die Notwendigkeit einer vollständigen Kopie. Dadurch werden Ressourcen effizienter genutzt.
– Versionskontrolle: Snapshots sind nützlich, um verschiedene Versionen von Daten oder Systemen zu verwalten. Dies ist in der Softwareentwicklung und im Datenbankmanagement von großer Bedeutung.
Funktionsweise von Snapshots
Die Funktionsweise von Snapshots kann je nach der Art der IT-Umgebung variieren. In der Regel wird jedoch ein Snapshot erstellt, indem ein Bild des aktuellen Zustands einer Ressource gemacht wird. Dieses Bild enthält alle relevanten Daten und Metadaten, um den Zustand vollständig zu rekonstruieren. Der Snapshot wird separat gespeichert, unabhängig von der ursprünglichen Ressource.
Es ist wichtig zu beachten, dass Snapshots in der Regel schreibgeschützt sind, um den Zustand zu bewahren und unbeabsichtigte Änderungen zu verhindern. Falls erforderlich, können Benutzer den Snapshot in der Regel jedoch in eine aktive Ressource umwandeln, um Änderungen vorzunehmen.
Vor- und Nachteile von Snapshots
Vorteile von Snapshots sind die Fähigkeit zur schnellen Wiederherstellung von Daten, die Unterstützung für effiziente Ressourcennutzung und die einfache Verwaltung von Versionen. Sie sind jedoch nicht für alle Szenarien geeignet. Snapshots erfordern zusätzlichen Speicherplatz und können die Leistung beeinträchtigen, wenn sie missbräuchlich verwendet werden.
Insgesamt sind Snapshots ein wertvolles Werkzeug in der IT, das dazu beiträgt, Daten und Systeme zu schützen, Fehler zu beheben und die Effizienz zu steigern. Die Verwendung von Snapshots erfordert jedoch eine sorgfältige Planung und Überwachung, um ihre Vorteile optimal auszuschöpfen und mögliche Nachteile zu minimieren.
System wie TrueNAS, JovianDSS oder Proxmox von EUROstor finden Sie unter > Software Defined Storage
Was ist Storage Spaces Direct (S2D)?
S2D ist eine Software-definierte Speicherlösung, die auf Clustern von Standard-x86-Servern basiert. Sie ermöglicht es Unternehmen, ihre internen Speicherressourcen zu einem einzigen, hochverfügbaren und hochgradig skalierbaren Speicherpool zu kombinieren. Diese Speicherressourcen können dann von virtualisierten Workloads oder anderen Anwendungen genutzt werden, ohne dass dedizierte Speichersysteme erforderlich sind.
Vorteile von Storage Spaces Direct (S2D):
- Kosteneffizienz: S2D nutzt Standard-Hardwarekomponenten, was zu niedrigeren Anschaffungskosten führt, da dedizierte Speicherhardware vermieden wird.
- Skalierbarkeit: S2D ermöglicht eine einfache Erweiterung des Speicherpools, indem zusätzliche Server hinzugefügt werden. Dies sorgt für eine nahtlose Anpassung an wachsende Speicheranforderungen.
- Hohe Verfügbarkeit: S2D bietet integrierte Funktionen zur Gewährleistung der Hochverfügbarkeit, einschließlich Replikation von Daten zwischen Knoten und automatischer Fehlererkennung.
- Performance: Durch den Einsatz von SSDs und optimierter Caching-Mechanismen kann S2D beeindruckende Leistungswerte erreichen, die den Anforderungen anspruchsvoller Workloads gerecht werden.
Integration mit Windows Server:
S2D ist nahtlos in Windows Server integriert, was die Verwaltung und Bereitstellung erleichtert.
Software-Defined Storage: Die Software-definierte Natur von S2D bietet Flexibilität und erleichtert die Verwaltung von Speicherressourcen in virtuellen Umgebungen.
Anwendungsbereiche von Storage Spaces Direct (S2D):
S2D eignet sich besonders gut für Unternehmen, die kostengünstige und skalierbare Speicherlösungen benötigen. Zu den Anwendungsbereichen gehören:
Virtualisierte Umgebungen: S2D kann in Hyper-V-Clustern genutzt werden, um virtualisierte Workloads zu unterstützen.
Private Clouds: Unternehmen können S2D verwenden, um eine eigene private Cloud-Infrastruktur aufzubauen.
Datenspeicherung: S2D ist auch eine ideale Lösung für Datenspeicherung und Dateifreigaben.
Hochverfügbarkeitslösungen: Die integrierten Funktionen zur Fehlererkennung und -behebung machen S2D zu einer großartigen Wahl für hochverfügbare Umgebungen.
Insgesamt bietet Storage Spaces Direct (S2D) Unternehmen eine kostengünstige, hochverfügbare und skalierbare Lösung für die Verwaltung von Speicherressourcen. Mit seiner Integration in Windows Server und seinen beeindruckenden Leistungsfähigkeiten ist S2D eine vielversprechende Option für Organisationen, die ihre Speicherinfrastruktur optimieren möchten.
S2D Systeme von EUROstor finden Sie unter > ES-2000 Windows S2D Cluster
Tape als zuverlässige Datensicherungslösung:
Tape, auch Magnetband genannt, ist ein langjährig bewährtes Medium zur Datensicherung und Archivierung. Es bietet eine hohe Speicherkapazität und Langlebigkeit bei vergleichsweise niedrigen Kosten. Tapes sind in der Lage, große Datenmengen sicher zu speichern und können für langfristige Archivierungszwecke verwendet werden. Ihre Robustheit gegenüber Umwelteinflüssen wie Temperaturschwankungen und elektromagnetischen Störungen macht sie zu einer verlässlichen Wahl für die Datensicherung.
Die Rolle von Tape Libraries:
Tape Libraries sind spezielle Geräte, die entwickelt wurden, um die Verwaltung und Organisation von Tapes zu automatisieren. Diese Libraries beherbergen mehrere Tapes und ermöglichen es, sie in einem System zu katalogisieren und schnell darauf zuzugreifen. Eine Tape Library kann je nach Modell Hunderte bis Tausende von Tapes verwalten, was eine skalierbare Lösung für Unternehmen mit umfangreichen Datensicherungsanforderungen darstellt.
Vorteile von Tape und Tape Libraries:
- Langfristige Datenaufbewahrung: Tapes sind aufgrund ihrer Langlebigkeit und Beständigkeit gegen äußere Einflüsse ideal für die langfristige Datenaufbewahrung geeignet.
- Kosteneffizienz: Im Vergleich zu anderen Speichermedien bieten Tapes eine kostengünstige Lösung für die Sicherung großer Datenmengen.
- Skalierbarkeit: Tape Libraries können je nach Bedarf erweitert werden, um zusätzlichen Speicherplatz zu bieten, was eine flexible und skalierbare Lösung ermöglicht.
- Robustheit: Tapes sind robust und halten Umwelteinflüssen stand, was sie zu einer zuverlässigen Wahl für die Datensicherung in unterschiedlichen Umgebungen macht.
- Datensicherheit: Durch ihre physische Natur sind Tapes vor Online-Bedrohungen und Cyberangriffen geschützt.
Anwendungsbereiche von Tape und Tape Libraries:
Tape und Tape Libraries finden in einer Vielzahl von Anwendungsbereichen Anwendung, darunter:
- Unternehmenssicherung: Tapes werden oft als Teil der Disaster-Recovery- und Business-Continuity-Strategien von Unternehmen eingesetzt.
- Archivierung: Aufgrund ihrer Langlebigkeit und Kapazität sind Tapes eine ideale Lösung für die langfristige Archivierung von Daten.
- Medien und Unterhaltung: Die Unterhaltungsindustrie nutzt Tapes für die Speicherung von Filmmaterial, Musik und anderen digitalen Inhalten.
- Gesundheitswesen: Im Gesundheitswesen werden Tapes häufig für die sichere Aufbewahrung von Patientendaten und medizinischen Bildern verwendet.
Insgesamt sind Tape und Tape Libraries nach wie vor unverzichtbare Werkzeuge für die Datensicherung und Archivierung in Unternehmen. Ihre Kombination aus hoher Kapazität, Kosteneffizienz und Zuverlässigkeit macht sie zu einer wertvollen Ergänzung moderner Speicherlösungen in der Unternehmens-IT.
Passende Tapes und Tape Libraries von EUROstor finden Sie unter > Backup / Archivierung
VEEAM Immutable Backup ist eine Funktion, die das Löschen von Daten aus Backup-Repositories verhindert, indem sie diese Daten vorübergehend unveränderlich macht. Dies geschieht zur Erhöhung der Sicherheit: Unveränderlichkeit schützt Ihre Daten vor Verlusten infolge von Angriffen, Malware-Aktivitäten oder anderen schädlichen Aktionen.
Die Unveränderlichkeit von Backups bietet viele Vorteile:
- Datensicherheit und -integrität: Unveränderliche Backups können vor potenziellen Änderungen oder Löschungen geschützt werden, was bedeutet, dass die ursprüngliche Integrität der Daten erhalten bleibt.
- Schutz vor Ransomware: Mit dem Aufkommen von Ransomware ist ein unveränderliches Backup für die Wiederherstellung unerlässlich geworden.
- Wiederherstellung nach versehentlichem Löschen: Unveränderliche Backups helfen nicht nur bei der Wiederherstellung nach einem Ransomware-Vorfall, sondern dienen auch anderen Zwecken bei der Gestaltung und Implementierung einer widerstandsfähigen Datenprotektionsstrategie.
Die Unveränderlichkeit von Backups arbeitet mit Backup-Daten und zugehörigen Metadaten (Checkpoints) auf der Seite des Objektspeichers. Die Aufbewahrungsrichtlinie arbeitet mit der logischen Darstellung der gespeicherten Daten oder Wiederherstellungspunkten auf der Seite des Veeam-Agenten. Diese beiden Mechanismen agieren unabhängig voneinander.
Passende Produkte von EUROstor finden Sie hier > Veeam gegen Ransomware
ZFS, ein Open Source Dateisystem, entwickelt von ORACLE/Sun, hat sich in den letzten Jahren zu einem beliebten Filesystem in Rechenzentren und mittelständischen Unternehmen entwickelt.
In ZFS sind die Stärken von Redundanz, ausgereiftem Dateisystem und Performance vereint, bei nahezu unlimitierter Speicherkapazität. Die Skalierbarkeit eignet sich bestens für verschiedene Einsatzzwecke.
Das Dateisystem schreibt Daten mit dem Copy-on-Write Mechanismus. Dieser unterscheidet sich vom gewöhnlichen Read-Write-Modify Verfahren darin, dass Blöcke, welche geändert werden sollen nicht zuerst gelesen, und dieselben Blöcke dann überschrieben werden müssen.
ZFS schreibt direkt einen neuen, zusätzlichen Block mit den Änderungen. Der alte Block bleibt in seiner Form also vorerst erhalten, was die Performance, aber auch die Sicherheit erhöht. Es entsteht kein Schreibloch wie z.B. bei RAID Technologien welche den Originalblock zuerst modifizieren müssen.
Durch Copy-on-Write lassen sich Snapshots ohne Performanceverlust zu erzeugen, was die Vorteile für Desaster Recovery oder Backup offensichtlich macht. Da alte Datenstände nicht überschrieben werden, können schnell viele Snapshots, verschiedener Zeiten und Versionen erstellt werden und ebenso schnell der entsprechende Datenbestand wiederhergestellt werden.
Auch „self-healing“ bringt das Dateisystem mit sich. Ein prüfsummenbasierter End-to-End Schutz überprüft in regelmäßigen Abständen die Korrektheit der Blöcke. Das verhindert Datenkorruption.
Die Prüfsummen werden ebenfalls beim Schreiben der Blöcke erstellt und in eigene Blöcke geschrieben, was die Überprüfung der Konsistenz performant hält und neben Bit Rot auch falsch adressierte Schreibvorgänge immer wieder ausgleichen kann. Datei bzw. Blockfehler werden daher automatisch „geheilt“.
Um die Performance weiter zu erhöhen können Read und Write Caches zugeschaltet werden, wenn statt SSDs herkömmliche große Festplatten verwendet werden.
Bei der Redundanz auf Disk Ebene werden die Vorteile des klassischen RAID mit dem flexiblem ZFS- Dateisystems kombiniert:
– Mirror (entspricht RAID 1)
– RAID-Z1 (1 Parity-Bit, wie RAID 5)
– RAID-Z2 (2 Parity-Bits, wie RAID 6)
– RAID-Z3 (3 Parity-Bits)
Sowohl Netzwerk, als auch Massenspeicherprotokolle (CIFS, NFS, iSCSI und FC) sind in ZFS Systemen bereits integriert und können ohne zusätzlichen Aufwand direkt aus den Pools bereitgestellt werden.
ZFS- Systeme von EUROstor finden Sie hier > Software Defined Storage
+49 (0) 711 – 70 70 91 70
Unsere Storage-Experten beraten Sie
Mo-Do: 08-18Uhr / Fr: 08-17Uhr
+49 (0) 711 – 70 70 91 80
Pre- oder Postsales Support
Mo-Do: 08-18Uhr / Fr: 08-17Uhr
Nehmen Sie Kontakt auf
» zum Kontaktformular
Schnelles Feedback bei Anfragen aller Art, egal ob Vertrieb oder Service
Storage-Newsletter
Die aktuelle Ausgabe können Sie hier downloaden.