
Storage Know-how – Information about our storage systems
ZFS, an open source file system developed by ORACLE/Sun, has become a popular file system in data centres and medium-sized companies in recent years.
ZFS combines the strengths of redundancy, elaborated file system and performance with almost unlimited storage capacity. The scalability is ideally suited for various purposes.
The file system writes data with the copy-on-write mechanism. This differs from the usual read-write-modify procedure in that blocks that have to be changed are not read first and the same blocks must then be overwritten.
ZFS directly writes a new, additional block with the changes. The old block thus remains unchanged for the time being, which increases performance, but also security. There is no write hole as with RAID technologies, for example, which have to modify the original block first.
Copy-on-write allows snapshots to be created without loss of performance, which makes the advantages for disaster recovery or backup obvious. Since old data is not overwritten, many snapshots of different times and versions can be created quickly and the corresponding data stock can be restored just as quickly.
The file system also offers „self-healing„. A checksum-based end-to-end protection checks the correctness of the blocks at regular intervals. This prevents data corruption.
The checksums are also created when the blocks are written and they are written to special blocks, which keeps the consistency check performant and can always compensate for incorrectly addressed writes in addition to bit rot. File or block errors are therefore automatically „healed“.
To further increase performance, read and write caches can be defined if conventional large hard disks are used instead of SSDs.
Redundancy at the disk level combines the advantages of classic RAID with the flexible ZFS file system:
– Mirror (corresponds to RAID 1)
– RAID-Z1 (1 parity bit, like RAID 5)
– RAID-Z2 (2 parity bits, like RAID 6)
– RAID-Z3 (3 parity bits)
Both network and mass storage protocols (CIFS, NFS, iSCSI and FC) are already integrated in ZFS systems and can be provided directly from the pools without additional effort.
Block, File and Object Storage
Block, file and object are storage formats used to store data in different ways. Each has its advantages and disadvantages.
Briefly summarized: Block storage simply offers a series of data blocks to the client, file storage works via a folder hierarchy (file system) and object storage manages the data directly with its corresponding metadata and across many storage systems, as is usual in the cloud.
Block storage
Block storage is based on a simple method of data storage. Individual physical blocks on the data disks (HDD/SSD/NVMe) are addressed. Each block is given a kind of house number, called an index. If a file is written, this file consists of several blocks and the client „remembers“ the index of the blocks that form this file.
The storage system makes these blocks available to a computer. The computer must manage the indices itself, either by formatting the volume and writing it with a file system of its choice, or by using it as a raw device. The intelligence is therefore not on the storage, but on the accessing system. An external block storage system is therefore treated like an internal hard disk. A RAID array of many disks is then presented as one large (virtual) disk, block by block.
Block storage is usually used directly attached or in a SAN (Storage Area Network) environment. The common protocols for access via block storage are SAS (direct attached only), Fibre Channel and iSCSI (direct attached or via a switch).
This simple principle enables low latencies, as no significant computing effort is required in the storage or on the operating system side when querying the data. On the other hand, a block volume is only available to one computer or computer cluster. Filestorage is preferable for access by several computers.
Filestorage
File storage is also called hierarchical storage, because in contrast to block storage, not only individual blocks are addressed, but entire files via a file system path. The client must therefore know the path in order to access the file. Several blocks are directly combined as a file and stored together with a limited number of metadata on the storage. Because of the file system management, storage requires additional computing power in the storage itself. Sufficient main memory is required for this.
File storage is also known as NAS (Network Attached Storage). The storage itself organises the file system, the hierarchical structure and the storage of metadata.
The most common network file systems are CIFS (Windows) and NFS (Unix, Linux). The main advantage of file storage is that several clients can access the same file system. With block storage, this is only possible via a dedicated cluster file system.
Object storage
With object storage, all blocks are stored unstructured in a large pool or in a single directory and can be recognized by other applications on the basis of the associated metadata. It is no longer just a single block or a single file that is managed, but the entire object with its metadata. This storage solution is particularly suitable for relatively static files, large amounts of data (big data) and cloud storage. The common protocols for access via object storage are REST APIs and SOAP (Simple Object Access Protocol) via HTTP(S).
The advantage of object storage is its ease of use and almost infinite scalability across individual storage systems. Object is also independent of the client system, and any number of clients can access it simultaneously.
Because not only individual blocks or files are viewed, but the entire object with all its metadata, object storage is not necessarily suitable for applications that require low latencies, such as databases, etc. The object storage system is also independent of the client system.
Before 1987, data for companies and mainframes was mostly backed up on single large and very expensive storage blocks. Smaller and cheaper hard disks were mainly for personal computers.
As the importance and amount of data increased, companies could no longer afford to lose this single large disc. All data was lost if the disc failed.
This gave rise to the idea of connecting several small hard disks together to form a larger logical group in order to distribute the costs over many small disks and to ensure that a single small disk could fail without losing the logical group and the data on it.
The term RAID – Redundant Array for Inexpensive Disks was born. The data was written distributed over several hard disks and received additional information on the respective blocks. So-called redundancy information or parity data. From this parity data, the CPU could reconstruct failed data blocks onto new hard disks.
Thus, a part of the network could fail, which could be restored by the redundancy blocks on new unrecorded hard disks.
Since large individual disks are a thing of the past and reliability and performance play a greater role for companies than price, RAID is now referred to as a „Redundant Array of *Independent* Disks“.
In addition, it had a speed advantage if a file could be written or read distributed over several hard disks, as here access to the individual blocks takes place in parallel.
The RAID levels
The different RAID levels distinguish the type of connection between the individual hard disks. Redundancy, speed and capacity are the decisive factors.
The most common RAID levels are RAID 0, RAID 1, RAID 10, RAID 5 (50) and RAID 6 (60).
With RAID 0, data is written evenly across all disks (striping), which increases performance and creates a large virtual disk, but there is no redundancy, i.e. the failure of one disk leads to the failure of the entire RAID. RAID 0 is therefore only used when fast access is required, but the data can be recovered at any time in the event of a failure.
With RAID 1, two hard disks are mirrored with each other, which is why it is also called a „mirror„. The RAID controller does not have to calculate any parity data, as each written block is simply written to both disks. If one of the hard disks fails, the other hard disk holds exactly the same data and can mirror it again when it is replaced by a new hard disk. By mirroring each data block, the capacity is that of one of the hard disks in the mirror, i.e. 50% of the total capacity of the array.
The write performance is also the same as that of one hard disk, but when reading, a part of the requested data can be read from both hard disks in parallel, which increases the read performance of RAID1.
A RAID 10 is a group of several RAID 1 mirrors, the data is distributed over all mirrors (striping), thus a large number of hard disk mirrors can be realized in a logical group. The performance increases accordingly, as with RAID 0, but the overlap is 50%.
With RAID 5, the data is striped as with RAID 0, but the parity is written to one of the disks via the other disks. Thus, if one disk fails, the missing data can be reconstructed from all other disks plus the parity information. To ensure an even load on the disk access, the parity information per data set is distributed to alternating disks. Otherwise, the parity disk would also have to be written to with every write access, which would significantly reduce performance. The offcut here is n-1 (for example, with 12 disks, the capacity of 11 is available).
RAID 6 uses a complex mathematical procedure to calculate double parity. Here, two disks can fail without data loss. The effort leads to a somewhat lower performance but is justified: Since a rebuild of a disk may take many hours, with RAID 5 even a single read error on another disk would no longer be correctable in this time. The overlap here is n-2, since the capacity of two disks is used for double parity.
With RAID 50 or 60, several RAID 5/6 sets are combined into one stripe set. This means that one or two hard disks per set can fail without data loss.
Which RAID level is optimal?
That depends on the application, of course. RAID 10 is very secure and, above all, fast, but costs the use of twice as many hard disks. For large, spinning disks, RAID 6 is usually strongly recommended. With SSDs, depending on the performance requirements, RAID 10 (more expensive) or RAID 5 is used (significantly better performance than RAID 6, but the rebuild does not take as long, so the risk is lower).
Hardware RAID – Software RAID
A RAID set is either realized by a dedicated controller with its own processor (hardware RAID), but can also be created by the operating system of a computer itself (software RAID). The latter is the case, for example, when two boot disks are mirrored as RAID 1. In most other cases and of course with external storage, a RAID controller is usually better performing and easier to manage.
EUROstor RAID systems can be found here.
Even the best high-availability storage solutions do not protect against data loss: If data is accidentally deleted, overwritten, or – even worse – encrypted by ransomware, no amount of redundancy will help. Because then this also affects the mirrored data.
Generally, two types of backup are distinguished: Backup to Tape and Backup to Disk.
Backup to Tape
Traditionally, backups are written to magnetic tapes (today mostly in LTO format). The advantage is that the tapes can be stored for up to 30 years under correct storage conditions, such as humidity and temperature. When stored securely, they are protected from alteration, save power, and are cheaper than disks for large capacities.
However, when it comes to recovering the data, they are slow: recovery may take several days for large amounts of data. Recovery of individual files is also lengthy. Although there are now also LTOs with their own file system, even then the latency is very high because the tape has to rewind to the relevant location.
For this reason, backup to disk is now usually used for long-term archiving or as a second backup level behind a current disk backup.
Backup to Disk
Backup software usually also supports backing up files to hard disks or SSDs, as virtual tapes (which are ultimately large files managed like tapes) or, more commonly, as backup files of flexible size in a normal file system.
Backup to disk is much faster due to random access to the data, but correspondingly more expensive to purchase and to operate.
Especially when backing up virtual machines (VMs), random access can be a significant advantage: software manufacturers such as Veeam support „Instant Recovery“, where a virtual machine is started directly from the backup. This makes the data available again in minutes. The prerequisite for this is the use of high-speed disks or, better, SSDs.
Full backup – Incremental backup
Making a full backup every day is time-consuming and requires a lot of storage space. Therefore, a full backup is generally made only once in a while (for example, at the weekend). The further backups are then incremental, i.e. only the changed data is backed up. The data status at a point in time can then be reconstructed from the full backup and the incremental backups. Some software also offers the possibility to create a new full backup from a full backup and the previous incremental backups, so that the data does not have to be completely backed up again (backup consolidation).
Backup strategies
A suitable backup strategy is essential to keep the required capacity as low as possible on the one hand, but on the other hand to keep older data available in case of emergency. For example, a full backup is made once a week, and an incremental backup is made daily. The full backups are then outsourced beyond that, e.g. weekly for 4 weeks, monthly for a year and then annually. The storage time of a backup is called retention time.
Defining the backup strategy is essential for planning the backup hardware, i.e. how much disk and tape storage space is needed in total.
Backup and snapshots
Snapshots are a good way to create backups. On their own, they do not form a true backup, because in the event of a hardware failure, they are also lost. But they can be used as a basis for a backup, e.g. to run the backup in the background from a snapshot, while data can still be modified. But the snapshot data can also be backed up by asynchronous replication to a second replicated system. The ZFS file system supports this method. This is used, for example, in the On- & Off-Site Data Protection (OODP) of the Open-E JovianDSS software.
Backup as protection against Ransomware
To provide protection against ransomware, backups must not be in direct access of a file system. Outsourced tapes or hard disks protect against this, but so do backup systems that are only accessible by the backup software itself. Such solutions are offered, for example, by Veeam with its „Hardened Linux Immutable Repository“ technology, but also by systems that are based on asynchronous snapshot replication and whose volumes are only released for external access in an emergency.
Remote Direct Memory Access (RDMA)
RDMA, as the name suggests, enables the direct exchange of data in RAM between two or more servers. The exchange of data is independent of CPU, cache or operating system. A transport protocol implemented directly in the network card (RoCE/IWARP/InfiniBand) allows data to be passed between two RDMA-capable servers with much higher throughputs and significantly lower latency.
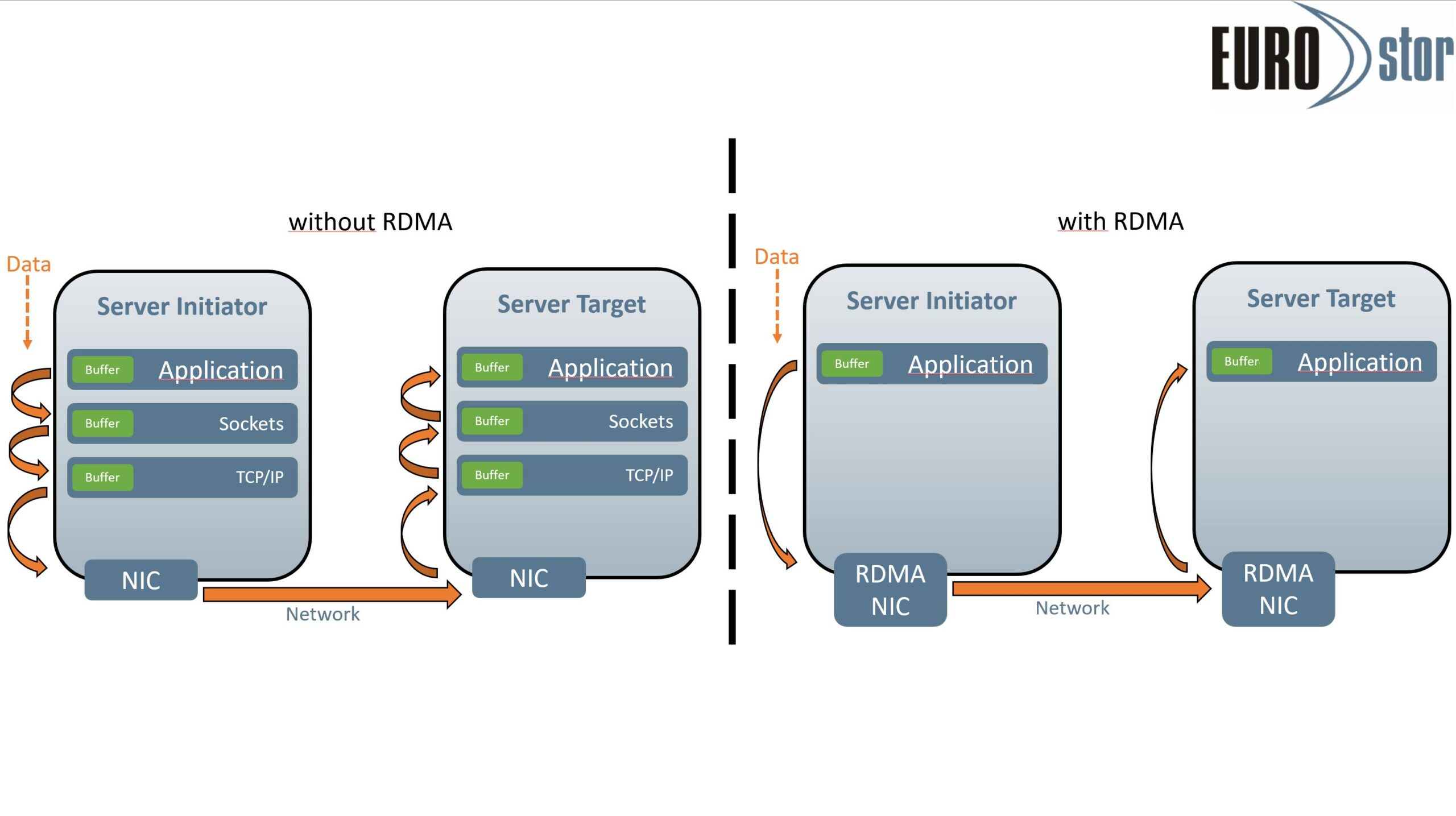
The application data in memory can be sent directly to the RDMA NIC, which then uses one of the RDMA protocols to send it over the network to the other RDMA capable server. The RDMA NIC on the target then passes the data directly to the RAM without relying on CPU, drivers or other network protocols.
RDMA can also be set up over existing Ethernet infrastructures, it is not necessary to adapt the complete network structure to RDMA.
- RDMA over Converged Ethernet (RoCE) enables RDMA on existing Ethernet networks.
- Internet Wide Area RDMA Protocol (IWARP) uses the TCP or SCTP protocol.
- For InfiniBand, RDMA is the standard protocol and is often used in HPC environments.
HPC, Big Data or supercomputing are the areas in which RDMA is frequently used. But also, the reduction of workloads for databases lends itself.
RDMA is particularly suitable for full flash systems with SSDs or NVMe. In the past, the low response time of flash memory was nullified by network protocols, controllers, etc. The bottleneck was then no longer the storage medium itself, as with HDDs.
NVDIMMs (Non-volatile Dual In-Line Memory Modules), are working memory modules with the ability to store data permanently. NVDIMMs are therefore ideal for SAN systems in data centers. In combination with RDMA, they provide an easy-to-implement and high-performance solution for cross-housing and high-availability cluster systems.
Full Flash is the term used for systems in which data is stored exclusively on non-volatile enterprise chips.
Colloquially, these are „Solid State Drives“ (SSDs) or also „Enterprise Flash Drives“ (EFDs). Enterprise Flash Drives differ from ordinary desktop SSDs by high IOPS requirements and more extensive specifications and are therefore suitable for critical enterprise operations. We generally only use enterprise SSDs.
The advantage over conventional hard disk drives (HDDs) is primarily the speed at which data blocks can be written or read. In addition, they are not sensitive to vibrations.
Flash memory does not require rotating cylinders, motors and sensitive read/write heads as is the case with hard disk drives.
This allows for much faster access time to individual data blocks. Latency is also many times lower due to the elimination of physical spinning disks, as there is no need to wait for the block to pass the read head as well.
The lack of vibration and lower power consumption also benefits durability and temperature development compared to HDDs. Which, in addition to lower power costs, is also reflected in the lower failure rates compared to SSDs.
Instead of SAS or SATA, SSDs are increasingly connected with NVMe (Nonvolatile Memory / PCIexpress – non-volatile mass storage via PCIexpress). This enables even higher throughput with even lower latency through direct access via PCIe interface.
NVMe SSDs are available in various designs. As PCIe cards they are plugged directly into PCIe slots, as small, compact M.2 models directly onto the motherboard (usually as boot media). For use in hot-swap canisters, U.2 and U.3 are available as standard.
The market is moving further and further in the direction of flash memory. The cost ratio of SSDs to HDDs at 7200 RPM was about 37:1 per TB in 2013. In 2021 this has fallen to 4,2:1.According to current estimates, flash storage will have caught up with HDDs in terms of price per TB by 2026 and will probably even be cheaper than HDDs. Therefore, 15K rpm drives no longer play a role today and 10K is also disappearing more and more from the market.
FullFlash storage systems from EUROstor can be found here.
High availability (HA) is the term used to describe systems that have an availability of 99%+. This concept is therefore essential for the long-term operation of the infrastructure.
High availability can be local, across fire protection zones or even geo-redundant.
For example, a system that has high availability in a single room is not available if that room as a whole is no longer accessible. It is therefore important to know which type of high availability makes sense and is necessary for one’s own infrastructure.
High availability is defined by two or more (independent) systems that can actively access the infrastructure, so that if one of the systems fails, the other can automatically take over the services. Individual hardware components can therefore fail without affecting operations. This is often referred to as „No Single Point of Failure“ NOSPF.
A standby system that must first be integrated into the active infrastructure can at best be described as a disaster recovery solution. The classic RAID also offers high availability only within its own network (locally, in relation to the disks/SSDs).
Two computers or storage systems that together form a highly available system are called HA clusters. If one of the systems is in standby mode and only takes over in the event of a fault, this is called an active/passive cluster. If both are active and also take over the tasks of the other system in the event of a fault, it is an active/active cluster. It is important that the system takes over automatically in the event of an error, without manual intervention.
Maximum security and availability is achieved by combining cluster systems with replication to a disaster recovery system. The ZFS file system offers features to achieve this.
EUROstor HA storage cluster can be found here.
Direct Attached Storage (DAS) or Network Storage (NAS/SAN)?
When connecting the RAID systems to the host computer, the first question is whether the systems should be connected directly to the computer (direct attached storage, DAS) or via a storage area network (SAN). The latter makes sense because here many systems – server and storage – can be connected to each other through switches. An extreme case is that only one server is connected with many RAIDs in order to obtain a lot of storage capacity with corresponding performance. But a network technology may also be necessary for direct-attached solutions, namely if distances have to be bridged that cannot be realized with SAS.
Either iSCSI or Fibre Channel is used for storage networks. Both have their respective advantages and disadvantages.
In all cases where a storage network does not have to be used, SAS is the less expensive alternative, as both the RAID controllers and the host adapters in computers are significantly cheaper.
Connecting a storage device as NAS (Network Attached Storage) is always recommended when several clients need to access the same file systems simultaneously. The connection is slower than the block-based technologies described above because it is file-based. If maximum access speed is required, the use of a cluster file system or corresponding software in conjunction with a block-based storage solution is recommended for shared access.
| Feature | DAS | SAN | NAS |
| Bus | SAS | Fibre Channel or Ethernet | Ethernet |
| Distance | up to 6m | long distance, depending on cable | |
| Access | block level (seen as volumes that can be formatted by the accessing host) | file level | |
| Number Hosts | 1 or 2 (cluster) | many (over switches) | |
| Performance | fast | fast | slower |
| Cost | low | higher | medium |
Ceph is an open-source storage solution for Linux systems that has its own file system, CephFS. By storing data on several individual systems, Ceph is enormously flexible and offers high scale-out potential.
Ceph was developed under the assumption that all components of the system (hard disks, hosts, networks) can fail and traditionally uses replication to ensure data consistency and reliability.
Ceph is supported on CentOS, Debian, Fedora, Red Hat / RHEL, OpenSUSE and Ubuntu, for example. But access from Windows systems is also possible. Ceph is used in medium to large data centres, is ideal for cloud solutions or for larger archive solutions in general.
The data is stored redundantly on different data disks, distributed across housings, and the reliability increases with the number of independent components.
The CRUSH placement algorithm (see below) allows the definition of failure domains across hosts, racks, rows or data centers, depending on the scale and requirements of the deployment.
The storage is presented contiguously, as one large storage. It can be accessed via a wide variety of protocols, be it NAS, iSCSI, object protocols or natively via CephFS. The translation is done by gateway daemons, which can be separate nodes or run as additional processes on the same systems.
Important components of a Ceph cluster:
Monitor Nodes (MON Node)
A MON Node is a daemon responsible for maintaining cluster membership. The MON Node creates a unified decision making for the distribution of data within the cluster. It requires few but always an odd number of MON Nodes in a system to make a quorum decision in case of inconsistency.
OSD Node (HDD/SSD)
For each HDD or SSD, a separate OSD daemon runs, which stores the objects (data blocks). Here, the actual data blocks are written and read, which were previously distributed via the CRUSH algorithm.
CRUSH („Controlled Replication under Scalable Hashing“)
The heart of the CEPH construct is CRUSH, this algorithm distributes the data blocks (objects) pseudo-randomly using an allocation table (CRUSH map). Pseudo-random because it is possible to intervene in the random algorithm and, for example, distribute the redundancy to different nodes, cabinets or fire protection zones. So-called placement groups then store the objects spatially redundant if desired.
Ceph Solutions by EUROstor can be found here.
+49 (0) 711 – 70 70 91 70
Unsere Storage-Experten beraten Sie
Mo-Do: 08-18Uhr / Fr: 08-17Uhr
+49 (0) 711 – 70 70 91 80
Pre- oder Postsales Support
Mo-Do: 08-18Uhr / Fr: 08-17Uhr
Nehmen Sie Kontakt auf
» zum Kontaktformular
Schnelles Feedback bei Anfragen aller Art, egal ob Vertrieb oder Service
Storage-Newsletter
Die aktuelle Ausgabe können Sie hier downloaden.